¡Hola! Si estás aquí es porque quieres complementar un poco tus conocimientos respecto de la recursión para entenderla mejor. Estás en el lugar indicado para hacerlo.
Mi objetivo con este post es el de darle un vistazo a la esencia de la recursión, ¿de qué estamos hablando exactamente cuando hablamos de recursión? ¿Qué no era solo sobre funciones que se llaman a sí mismas?
Vamos a explorar a continuación algunos ejemplos de fenómenos recursivos que ilustrarán bastante la idea de la recursión. Voy a tratar de no entrar en definiciones muy formales, porque quiero tratar de comunicarlo de una manera más conceptual y visual.
Pensamiento recursivo
Un fenómeno o sistema recursivo es aquel que está definido en términos de sí mismo (o mejor, que está definido en términos de elementos de una estructura o naturaleza muy similar).

Fuente: https://www.smbc-comics.com/comic/recursion
En ciencias de la computación recordaremos mucho problemas como el cálculo del factorial, la sucesión de Fibonacci, búsqueda y ordenamiento eficientes, etcétera, pero estamos cayendo en mecanizar demasiado el intentar solo ver a la recursión como "una forma rara de iterar en un nuevo nivel", y la recursión va mucho más allá de esto.
La idea de la recursión es aprovechar las características de un fenómeno o sistema en cuanto a sí mismo. Lo que quiero decir con esto es que para poder comprender un fenómeno o sistema complejo, debemos comprender sus partes, y a la vez las partes de sus partes, y así hasta dar con el grado de complejidad más pequeño. Una vez dominemos esto, podremos entender no solo a las partes mínimas del fenómeno o sistema, sino que también lograremos ver cómo cada nivel -diferente al mínimo- es un "todo", compuesto de un "todo" más pequeño... Así, cuando lleguemos al nivel más complejo, entenderemos ese "todo" como mucho más que solo la suma de sus partes.
Una analogía que me viene a la cabeza es la complejidad de un organismo vivo. El cuerpo humano, por ejemplo, es un "todo" complejo. Es un sistema, cuyos componentes en un nivel menor también son sistemas (sistema digestivo, circulatorio, etcétera). Luego cada uno de esos sistemas tiene como componentes otros sistemas (conjuntos de tejidos, que a su vez son sistemas de células, que a su vez son sistemas de organelas, que a su vez son sistemas de aminoácidos, etcétera, etcétera). Aquí el fenómeno recursivo es el de "sistema de componentes que son sistemas", y la naturaleza compartida es de la misma definición de sistema (partes que en conjunto forman un "todo" para cumplir una función de acuerdo a entradas para dar salidas). Este es un ejemplo de recursión de definición o de funcionalidad.
Entonces, lo que quiero resaltar de la recursión es que es algo con lo que podemos diseccionar y comprender fenómenos complejos con facilidad, aprovechando una característica en común en los niveles de complejidad de los mismos; no obstante, también la podemos usar para crear fenómenos complejos.
Fractales
Son quizás el ejemplo más clásico en cuanto a recursión de estructura.
Un fractal es un sistema geométrico compuesto por sistemas geométricos de menor nivel que comparten y replican una estructura similar.
Hay centenares de tipos de fractales definidos en varias dimensiones, reglas, patrones, e incluso bases numéricas. Exploremos unos ejemplos sencillos.
Círculos binarios internos
Es un fractal muy simple: Círculo grande, que tiene círculos más pequeños a la izquierda y la derecha, que tienen círculos más pequeños a la izquierda y la derecha, que tienen [...] Ok, ya paro... El asunto es que debe parar en algún punto, y eso es el caso base, que aquí corresponde a una circunferencia simple.
Podemos generalizarlo como el fractal C(R): círculo grande que tiene dos fractales C(R/2) en su interior, para un radio R (a la izquierda y la derecha del centro).
Notemos cómo se repite la regla de la estructura (el problema recursivo) en cada nivel de complejidad hasta llegar al caso base:

Árbol binario
Es un fractal clásico y simple donde la regla es "estirar y ramificar".
El caso base será una línea, y la definición recursiva es la regla que acabo de mencionar arriba, que funciona así:
Árbol nivel N:de la dirección del nivel actual4. Dibujar Árbol nivel N-1 en esa dirección y con tamaño reducido
Aquí un ejemplo de cómo se vería:

Nota que en cada nivel se refleja "Estirar" con un color distinto, siendo cada recta el tronco de cada sub-árbol.
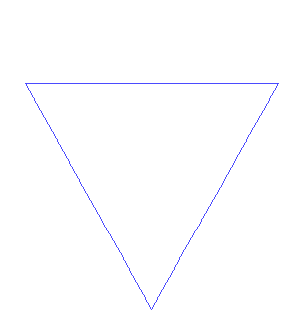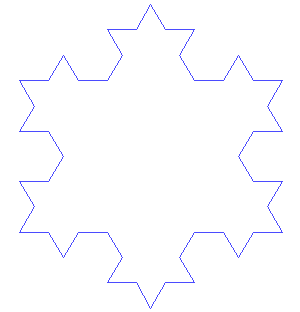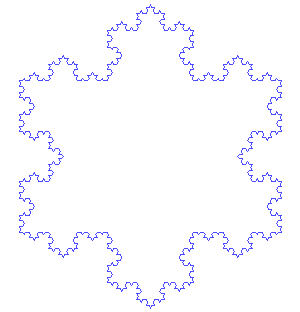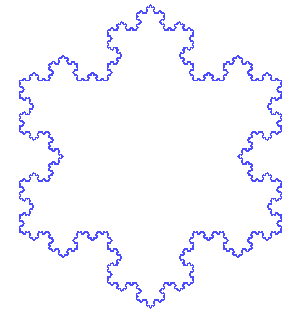
La curva de Koch
Para este fractal, el problema mínimo (nivel 0) es un segmento de recta, y el problema general en el nivel N se define así:
F <-- K+K-K+KParaF: Fractal nivel NK: Fractal nivel N-1-: Rotar 120 grados a la derecha+: Rotar 60 grados a la izquierda
Esta es una pequeña modificación a la definición formal del fractal como sistema de Lyndenmayer... pero no voy a entrar en detalle en formalidades para ser práctico y claro.
Eso de arriba se interpreta como:
1. Dibujar el subfractal de nivel más pequeño2. Rotar 60 grados a la izquierda3. Dibujar el subfractal de nivel más pequeño (en la posición final de 1.)4. Rotar 120 grados a la derecha5. Dibujar el subfractal de nivel más pequeño (en la posición final de 3.)
Ilustrado:

Jugando un poco con la definición de la curva de Koch, sobre una base de un triángulo equilátero, lleva a la obtención del copo de nieve de Koch:
Cortesía de António Miguel de Campos - Wikimedia Commons
Programación Dinámica
Bueno, ya vimos unos buenos ejemplos que ilustran el comportamiento recursivo a nivel de estructura, pero vamos a darle una mirada a un especial de la aplicación de la recursión en donde no haremos recursión.
"¿Pero qué cosas dice este sujeto?", estarás pensando y así es, no vamos a hacer que una función se llame así misma, sino que vamos a hacer que esa función se aproveche de la naturaleza recursiva del problema para resolverlo. ¡Ah! ¡Y para hallar soluciones óptimas de forma eficiente, además!
Ok, quizás lo anterior es parcialmente cierto respecto a "no hacer recursión". La programación dinámica tiene dos esquemas: Bottom-up y Top-down. El primero se implementa de forma iterativa (sin hacer recursión) y el segundo de forma recursiva (¡me atrapaste!). A lo que quiero llegar es que el caso del esquema Bottom-up se tiene una recursión por definición, más no por estructura, como sería en el esquema Top-down.
El caso no es tanto cuál esquema escojas, sino cómo estás entendiendo el problema en términos de subproblemas que tienen su misma naturaleza. Vamos a valernos de esa propiedad para resolver problemas en todos los niveles de complejidad, partiendo de la solución sus subproblemas.
Lo anterior también es importante para el tema de hallar una solución óptima (es decir de máximos y mínimos). La naturaleza recursiva del problema hace que lo podamos definir como un problema de optimización basado en soluciones óptimas a los subproblemas, cosa que se repite recursivamente en todos los niveles de complejidad. A esto se le conoce como Subestructura Óptima y es la clave para garantizar que la solución en el nivel superior es la óptima de todo el problema.
Para ver una explicación más detallada, revisa mi post "Fundamentos de Programación Dinámica".
Conclusiones y recursos
Hemos visto que hacer recursión es más que solo llamar una función a sí misma, es pensar en cómo se replica la esencia de cualquier fenómeno o sistema en sus niveles de complejidad inferiores (el caso de las funciones siendo una particularidad de esto).
Aprender a dominar la recursión en formas tanto conceptual como algorítmica es clave para abordar con mucha más facilidad cualquier disección o creación de fenómenos o sistemas complejos, que se puedan definir de manera recursiva en funcionalidad o en estructura.
A pesar de que la recursión simplifica la solución de muchos tipos de problema de una forma elegante, hay que recordar que la pila de llamados de funciones en memoria es limitada, así que hay que evaluar muy bien si la recursión es la mejor forma de establecer dicha solución.
¿Te ha picado la curiosidad? Aquí te tengo algunas referencias adicionales para que explores un poco más:
- Recursion - Wikipedia (EN)
- Fractal - Wikipedia (EN)
- Fractal - Wikipedia (ES)
- The Nature of Code - Daniel Shiffman
- Recursion - LMU Computer Science
- Gödel, Escher, Bach: Una eterna trenza dorada - Douglas R. Hofstadter (es un libro que explora muchos sistemas y fenómenos recursivos, pero es más orientado hacia la contemplación filosófica de las formalidades matemáticas en cada uno)
Por supuesto, también es un tema que está al alcance de una Googleada, ya que es un tema muy popular; aparece y tiene aplicación en muchas áreas: arte, lenguajes, música, naturaleza, ingeniería, matemática, y ciencias de la computación (tanto en la algoritmia como en la creación de sistemas inteligentes). Hay miles de sitios Web que lo cubren de muchas maneras, por lo que estoy seguro que en unos minutos de investigarlo darás con gran número de temas interesantes.
Ha sido todo un gusto cubrir el tema de la forma más sintetizada posible.
¡Nunca pares de aprender!
Si tienes algún feedback, duda o comentario, puedes encontrarme en LinkedIn como Juan Camilo Álvarez Jurado (jcalvarezj) y en Twitter como @jcalvarezj8. Sígueme también en GitHub como jcalvarezj.



















